Blog :: Reverse Engineering Babby's First Archive Format
About two months have passed since the first release of Nekopack - a tool I wrote for extracting game data from Nekopara's XP3 archives. While the process wasn't an amazing reverse-engineering war story that will keep you on the edge of your seat, I feel it deserves a small blog post explaining how I did it. Additionally, there's no real documentation on the XP3 format as far as I'm aware, so hopefully this post will serve as an informal specification.
The first step I took was to see if anyone else had tried to reverse it. Even something as simple as a writeup would have made my goal significantly more attainable. The closest thing I was able to find was Arc Unpacker, a tool capable of extracting several archive formats, including XP3. However, attempting to use it brought to my attention the fact that Nekopara's archives are encrypted. Further searching yielded nothing of interest, so it seemed that the solution was to write a tool of my own. I chose to write it from scratch, as I couldn't predict how complex the encryption algorithm would be.
Writing a tool to work with an archive format, however, requires a very thorough understanding of how it's structured. Instinctively, I fired up my favorite hex editor and went at it, with the source code of Arc open to figure out most of it.
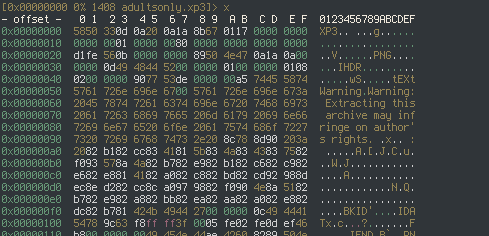
The first section of the archive is the header. It begins with an 11-byte "magic number," used by whatever program is opening it as a sanity check. It's followed by a 64-bit offset which, for XP3 version 2, points to a few adjacent values. First, an 8-bit integer that I've been told acts as a flags variable, followed by a 64-bit integer representing the table's size, and finally another 64-bit integer containing an offset to the beginning of the table section. The flags variable, to my knowledge, should have the 0x80 bit set; it's a constant defined in the code of the KiriKiriZ engine that I presume marks compatibility with the game engine. Byte 0x13 is a 32-bit unsigned integer representing the version, where a value of 1 represents version 2 of the archive.
The header can be represented as the following C struct.
struct header {
char magic[11];
uint64_t info_offset;
uint32_t version;
uint64_t table_size;
uint8_t flags;
uint64_t table_offset;
};
Seeking to the table, we find that it starts with some metadata. First, an 8-bit unsigned integer representing whether or not the contents of the archive are compressed. That's followed by a 64-bit unsigned integer representing the compressed size of the table, and another 64-bit unsigned integer representing the decompressed size. The table's contents are compressed using LZ77 and Huffman Coding, so let's use zlib! I proceeded to inflate the archive contents according to the header and dumped it so that I could view it in my hex editor.
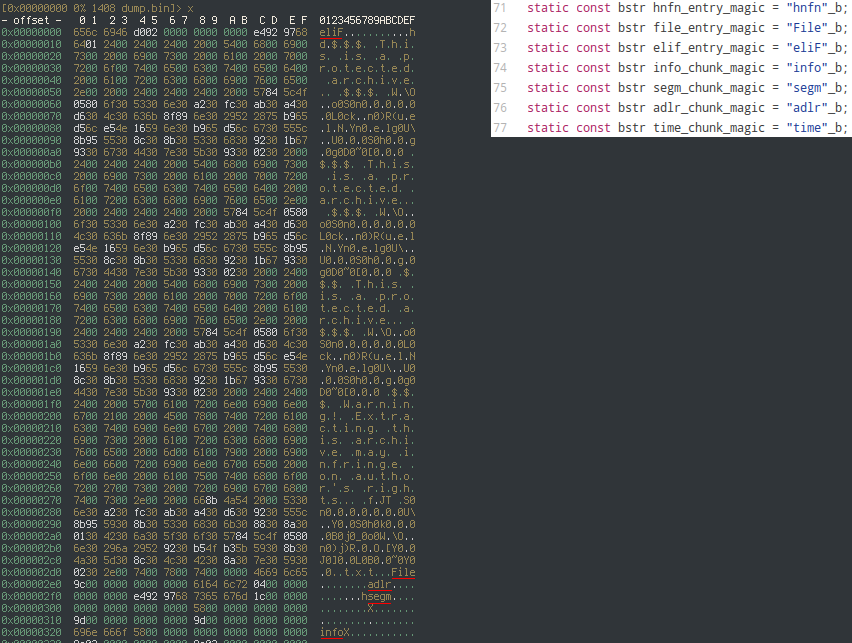
Every entry has a header containing a 32-bit magic number (underlined in red),
followed by a 64-bit unsigned integer representing the size of the entry. It's a
very simple format to parse. This very first entry, 0x656c6946, is an eliF
entry. It contains a UTF-16LE encoded filename and a "key", which is used to
associate the eliF entry with its corresponding File entry. That key is also
used when decrypting the file, but we'll get into that later on.
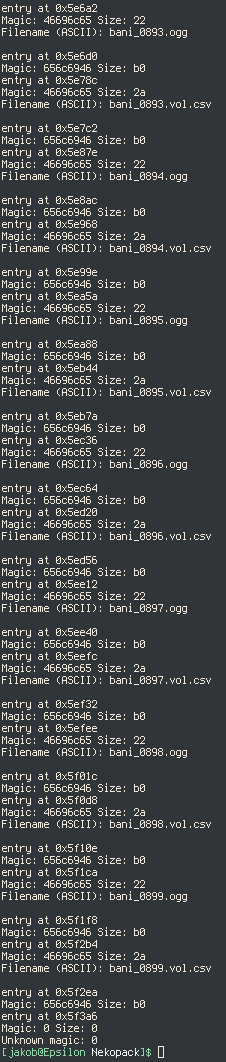
The next visible chunk is a File entry. There's a lot in it, so it's broken up
into several parts: info, segm, adlr, and time" The adlr chunk is
pretty small and contains only the key, used to match the File entry to an
eliF entry. The time chunk is also pretty small, containing a UNIX timestamp
for the file creation date. What's a little more interesting are the two
remaining chunks. segm has offsets to the beginning of the file, and it can
actually contain several "segments." The file chunks specified in segm are
also compressed with LZ77 and Huffman Coding. info contains a flags variable,
a compressed and decompressed size, and what seems to be an MD5 hash of the
file.
Now we run into the problem of the files' contents being encrypted. I began by getting a debugger setup going to reverse engineer the binary. x64dbg isn't my usual choice, especially not with Intel syntax, but it was the first thing I was really able to get working. Of course, using the debugger alone is a little primitive. We have other tools to make reverse engineering easier.
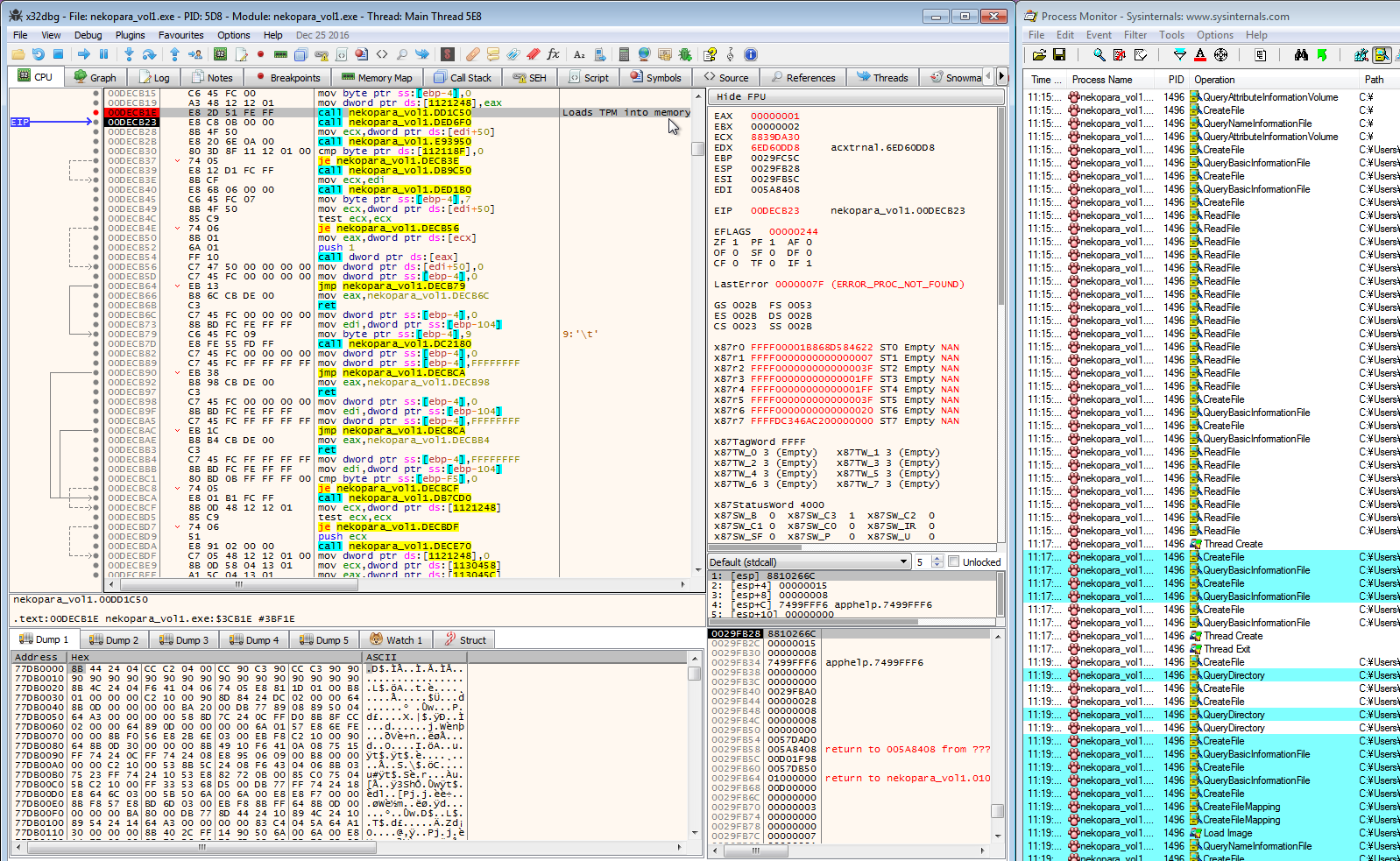
Enter procmon. It's reminiscent of strace, but it's meant for Windows and has a nice stack trace feature which helps us to locate the code that decrypts the archive. This is the point where I got stuck, having to deal with threads. It was mostly "guns blazing" debugging. I stepped through the code mindlessly for a few days, until one night before going to bed when I decided to take another look online for whether or not someone had cracked it yet. Then I found something interesting.
It felt a little too easy, but I already wrote the unpacking part - so I wrote code to decrypt buffers and copied the encryption keys into my code. Encryption is symmetric and extremely simple, just single-key xor. A base key is first derived by xoring the game's master key with the file key I mentioned earlier. Then a one-byte key is derived from that key by xoring each byte. For some games the least significant byte of the base key is used to encrypt the first byte of the file. The game has default values to fall back to if either of those keys are too simple.
Since the script I found only had the keys for volumes 1 and 0, I decided to try to get the key for volume 2 on my own. But now that I know the encryption algorithm used, I can break it without having to disassemble the game.
It's pretty simple. Most binary files have a "magic number" associated with them, which allows us to perform a known-plaintext attack. Pair that with the fact that the first byte of each file is encrypted with the least-significant byte of the base key, and you've got yourself a cracking process simple enough to do in about 100 lines of python.
Comments (0)
Leave a Comment